只要你和代码打交道,了解编译器的工作流程和原理定会让你受益无穷,无论是分析程序,还是基于它写自己的插件,甚至学习一门全新的语音。通过本文,将带你了解LLVM,并使用LLVM来完成一些有意思的事情。
一、什么是LLVM?
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies.
简单来说,LLVM项目是一系列分模块、可重用的编译工具链。它提供了一种代码编写良好的中间表示(IR),可以作为多种语言的后端,还可以提供与变成语言无关的优化和针对多种cpu的代码生成功能。
先来看下LLVM架构的主要组成部分:
- 前端:前端用来获取源代码然后将它转变为某种中间表示,我们可以选择不同的编译器来作为LLVM的前端,如gcc,clang。
- Pass(通常翻译为“流程”):Pass用来将程序的中间表示之间相互变换。一般情况下,Pass可以用来优化代码,这部分通常是我们关注的部分。
- 后端:后端用来生成实际的机器码。
虽然如今大多数编译器都采用的是这种架构,但是LLVM不同的就是对于不同的语言它都提供了同一种中间表示。传统的编译器的架构如下:

LLVM的架构如下:
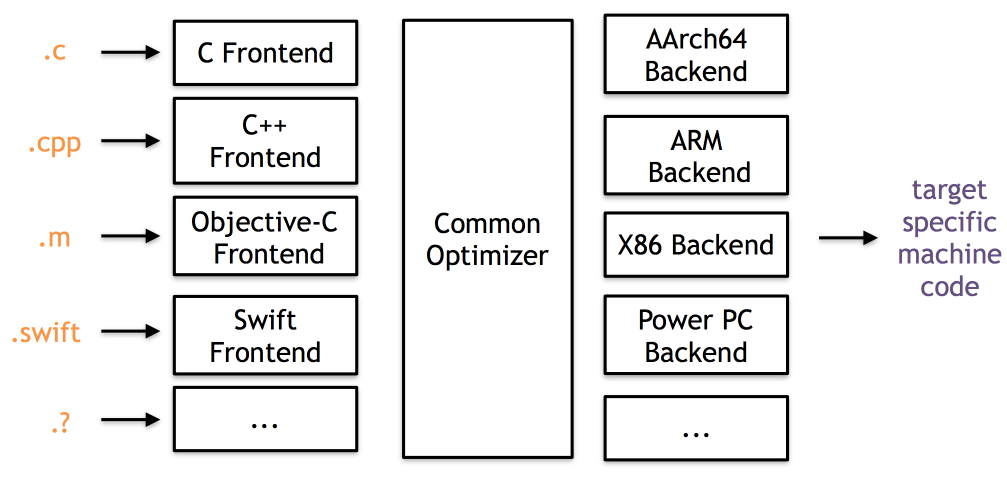
当编译器需要支持多种源代码和目标架构时,基于LLVM的架构,设计一门新的语言只需要去实现一个新的前端就行了,支持新的后端架构也只需要实现一个新的后端就行了。其它部分完成可以复用,就不用再重新设计一次了。
二、安装编译LLVM
这里使用clang作为前端:
1.直接从官网下载:http://releases.llvm.org/download.html
2.svn获取
1 | svn co http://llvm.org/svn/llvm-project/llvm/trunk llvm |
3.git获取
1 | git clone http://llvm.org/git/llvm.git |
最新的LLVM只支持cmake来编译了,首先安装cmake。
1 | brew install cmake |
编译:
1 | mkdir build |
编译时间比较长,而且编译结果会生成20G左右的文件。
编译完成后,就能在build/bin/目录下面找到生成的工具了。
三、从源码到可执行文件
我们在开发的时候的时候,如果想要生成一个可执行文件或应用,我们点击run就完事了,那么在点击run之后编译器背后又做了哪些事情呢?
我们先来一个例子:
1 | #import <Foundation/Foundation.h> |
上面这个文件,我们可以通过命令行直接编译,然后链接:
1 | xcrun -sdk iphoneos clang -arch armv7 -F Foundation -fobjc-arc -c main.m -o main.o |
拷贝到手机运行:
1 | monkeyde-iPhone:/tmp root# ./main |
大家不会以为就这样就完了吧,当然不是,我们要继续深入剖析。
3.1 预处理(Preprocess)
这部分包括macro宏的展开,import/include头文件的导入,以及#if等处理。
可以通过执行以下命令,来告诉clang只执行到预处理这一步:
1 | clang -E main.m |
执行完这个命令之后,我们会发现导入了很多的头文件内容。
1 | ...... |
可以看到上面的预处理已经把宏替换了,并且导入了头文件。但是这样的话会引入很多不会去改变的系统库比如Foundation,所以有了pch预处理文件,可以在这里去引入一些通用的头文件。
后来Xcode新建的项目里面去掉了pch文件,引入了moduels的概念,把一些通用的库打成modules的形式,然后导入,默认会加上-fmodules参数。
1 | clang -E -fmodules main.m |
这样的话,只需要@import一下就能导入对应库的modules模块了。
1 | @import Foundation; |
3.2 词法分析 (Lexical Analysis)
在预处理之后,就要进行词法分析了,将预处理过的代码转化成一个个Token,比如左括号、右括号、等于、字符串等等。
1 | clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m |
1 | annot_module_include '#import <F' Loc=<main.m:1:1> |
3.3 语法分析 (Semantic Analysis)
根据当前语言的语法,验证语法是否正确,并将所有节点组合成抽象语法树(AST)
1 | clang -fmodules -fsyntax-only -Xclang -ast-dump main.m |
1 | ...... |
语法树直观图:
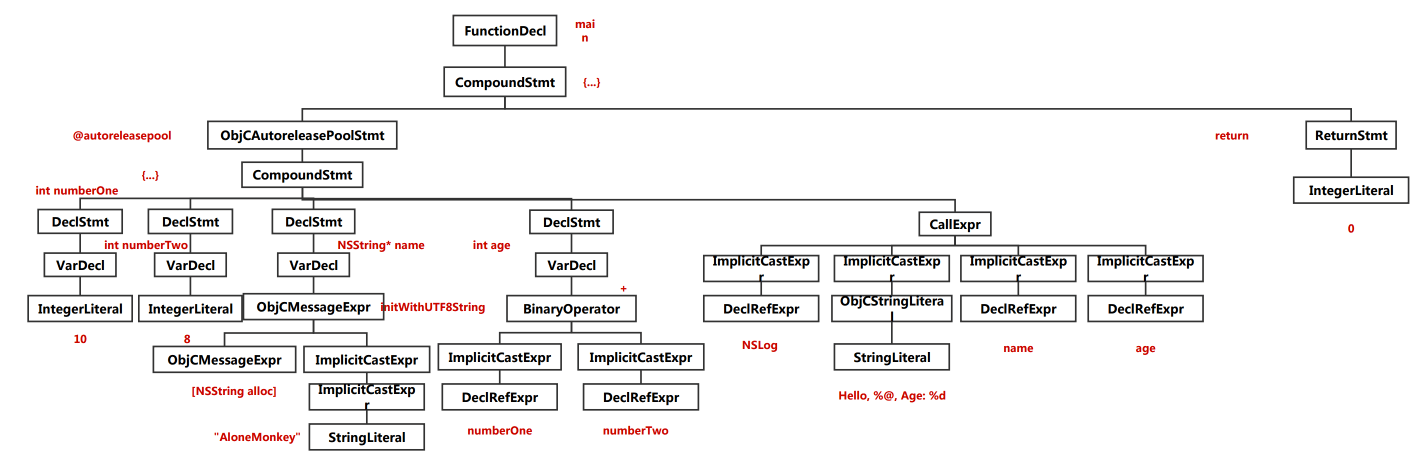
3.4 IR代码生成 (CodeGen)
CodeGen负责将语法树从顶至下遍历,翻译成LLVM IR,LLVM IR是Frontend的输出,也是LLVM Backerend的输入,桥接前后端。
可以在中间代码层次去做一些优化工作,我们在Xcode的编译设置里面也可以设置优化级别-O1,-O3,-Os。 还可以去写一些自己的Pass,这里需要解释一下什么是Pass。
Pass就是LLVM系统转化和优化的工作的一个节点,每个节点做一些工作,这些工作加起来就构成了LLVM整个系统的优化和转化。
1 | clang -S -fobjc-arc -emit-llvm main.m -o main.ll |
1 | ...... |
3.5 生成字节码 (LLVM Bitcode)
我们在Xcode7中默认生成bitcode就是这种的中间形式存在, 开启了bitcode,那么苹果后台拿到的就是这种中间代码,苹果可以对bitcode做一个进一步的优化,如果有新的后端架构,仍然可以用这份bitcode去生成。
1 | clang -emit-llvm -c main.m -o main.bc |
3.6 生成相关汇编
1 | clang -S -fobjc-arc main.m -o main.s |
1 | .section __TEXT,__text,regular,pure_instructions |
3.7 生成目标文件
1 | clang -fmodules -c main.m -o main.o |
3.8 生成可执行文件
1 | clang main.o -o main |
1 | 2016-12-20 15:25:42.299 main[8941:327306] Hello, AloneMonkey, Age: 18 |
3.9 整体流程

四、可以用Clang做什么?
4.1 libclang进行语法分析
可以使用libclang里面提供的方法对源文件进行语法分析,分析它的语法树,遍历语法树上面的每一个节点。可以用于检查拼写错误,或者做字符串加密。
来看一段代码的使用:
1 | void *hand = dlopen("/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/libclang.dylib",RTLD_LAZY); |
然后我们就可以在printVisitor这个函数里面去遍历输入文件的语法树了。
1 | 2016-12-20 16:25:44.006588 ParseClangLib[9525:368452] showString |
我们也通过通过python去调用用clang:
1 | pip install clang |
1 | #!/usr/bin/python |
1 | ....... |
那么基于语法树的分析,我们可以针对字符串做加密:
从左上角的明文字符串,处理成右下角的介个样子~
4.2 LibTooling
对语法树有完全的控制权,可以作为一个单独的命令使用,如:clang-format
1 | clang-format main.m |
我们也可以自己写一个这样的工具去遍历、访问、甚至修改语法树。 目录:llvm/tools/clang/tools
1 | #include "clang/Driver/Options.h" |
上面的代码通过遍历语法树,去修改里面的方法名和返回变量名:
1 | before: |
那么,我们看到LibTooling对代码的语法树有完全的控制,那么我们可以基于它去检查命名的规范,甚至做一个代码的转换,比如实现OC转Swift。
4.3 ClangPlugin
对语法树有完全的控制权,作为插件注入到编译流程中,可以影响build和决定编译过程。目录:llvm/tools/clang/examples
1 | #include "clang/Driver/Options.h" |
1 | clang -Xclang -load -Xclang ../build/lib/PluginExample.dylib -Xclang -plugin -Xclang -example-plugin -c testPlugin.c |
我们可以基于ClangPlugin做些什么事情呢?我们可以用来定义一些编码规范,比如代码风格检查,命名检查等等。下面是我写的判断类名前两个字母是不是大写的例子,如果不是报错。(当然这只是一个例子而已。。。)
五、动手写Pass
5.1 一个简单的Pass
前面我们说到,Pass就是LLVM系统转化和优化的工作的一个节点,当然我们也可以写一个这样的节点去做一些自己的优化工作或者其它的操作。下面我们来看一下一个简单Pass的编写流程:
1.创建头文件
1 | cd llvm/include/llvm/Transforms/ |
写入内容:
1 | #include "llvm/IR/Function.h" |
2.创建源文件
1 | cd llvm/lib/Transforms/ |
CMakeLists.txt:
1 | add_llvm_loadable_module(LLVMObfuscation |
LLVMBuild.txt:
1 | [component_0] |
SimplePass.cpp:
1 | #include "llvm/Transforms/Obfuscation/SimplePass.h" |
修改.../Transforms/LLVMBuild.txt, 加上刚刚写的模块Obfuscation
1 | subdirectories = Coroutines IPO InstCombine Instrumentation Scalar Utils Vectorize ObjCARC Obfuscation |
修改.../Transforms/CMakeLists.txt, 加上刚刚写的模块Obfuscation
1 | add_subdirectory(Obfuscation) |
编译生成:LLVMSimplePass.dylib
因为Pass是作用于中间代码,所以我们首先要生成一份中间代码:
1 | clang -emit-llvm -c test.c -o test.bc |
然后加载Pass优化:
1 | ../build/bin/opt -load ../build/lib/LLVMSimplePass.dylib -simplepass < test.bc > after_test.bc |
对比中间代码:
1 | llvm-dis test.bc -o test.ll |
1 | test.ll |
1 | after_test.ll |
这里写的Pass只是把a+b简单的替换成了a-(-b),只是一个演示,怎么去写自己的Pass,并且作用于代码。
5.2 将Pass加入PassManager管理
上面我们是单独去加载Pass动态库,这里我们将Pass加入PassManager,这样我们就可以直接通过clang的参数去加载我们的Pass了。
首先在llvm/lib/Transforms/IPO/PassManagerBuilder.cpp添加头文件。
1 | #include "llvm/Transforms/Obfuscation/SimplePass.h" |
然后添加如下语句:
1 | static cl::opt<bool> SimplePass("simplepass", cl::init(false), |
然后在populateModulePassManager这个函数中添加如下代码:
1 | MPM.add(createSimplePass(SimplePass)); |
最后在IPO这个目录的LLVMBuild.txt中添加库的支持,否则在编译的时候会提示链接错误。具体内容如下:
1 | required_libraries = Analysis Core InstCombine IRReader Linker Object ProfileData Scalar Support TransformUtils Vectorize Obfuscation |
修改Pass的CMakeLists.txt为静态库形式:
1 | add_llvm_library(LLVMObfuscation |
最后再编译一次。
那么我们可以这么去调用:
1 | ../build/bin/clang -mllvm -simplepass test.c -o after_test |
基于Pass,我们可以做什么? 我们可以编写自己的Pass去混淆代码,以增加他人反编译的难度。
我们可以把代码左上角的样子,变成右下角的样子,甚至更加复杂~
六、总结
上面说了那么说,来总结一下:
1.LLVM编译一个源文件的过程:
预处理 -> 词法分析 -> Token -> 语法分析 -> AST -> 代码生成 -> LLVM IR -> 优化 -> 生成汇编代码 -> Link -> 目标文件
2.基于LLVM,我们可以做什么?
- 做语法树分析,实现语言转换OC转Swift、JS or 其它语言,字符串加密。
- 编写ClangPlugin,命名规范,代码规范,扩展功能。
- 编写Pass,代码混淆优化。
这篇只是一个简单的入门介绍,个人还需要深入去学习LLVM,再给大家分享,如有问题,欢迎拍砖~


